May 9, 2026
Synthetic Data is a virtual recreation of real world data. It can be used to train Synthetic Computer Vision (SCV) models to detect real world objects.
In traditional Computer Vision (CV), the most widely used version of the technology, an algorithm is trained to detect real-world objects using hundreds and thousands of real images of those objects.
As you can imagine, sourcing and preparing this high-quality training data is extremely costly and time-consuming. The data gathering process makes it infeasible to adapt and scale the benefits of traditional Computer Vision to the demands of the masses. It is, therefore, unrealistic for most companies to consider its use for domain-specific applications.
To put it simply, the automation potential of Computer Vision and image recognition technology will remain out of reach for the majority of companies until the data problem is solved. Synthetic Data is the solution.
Practically speaking, Synthetic Data encompasses rendered images and videos of a 3D, digital twin of a real world object and the virtual scenes that it is placed in. This data represents the attributes of the object as well as possible environments in which it may be found in real life. It is used to train Computer Vision models to detect that real world object in varied contexts.
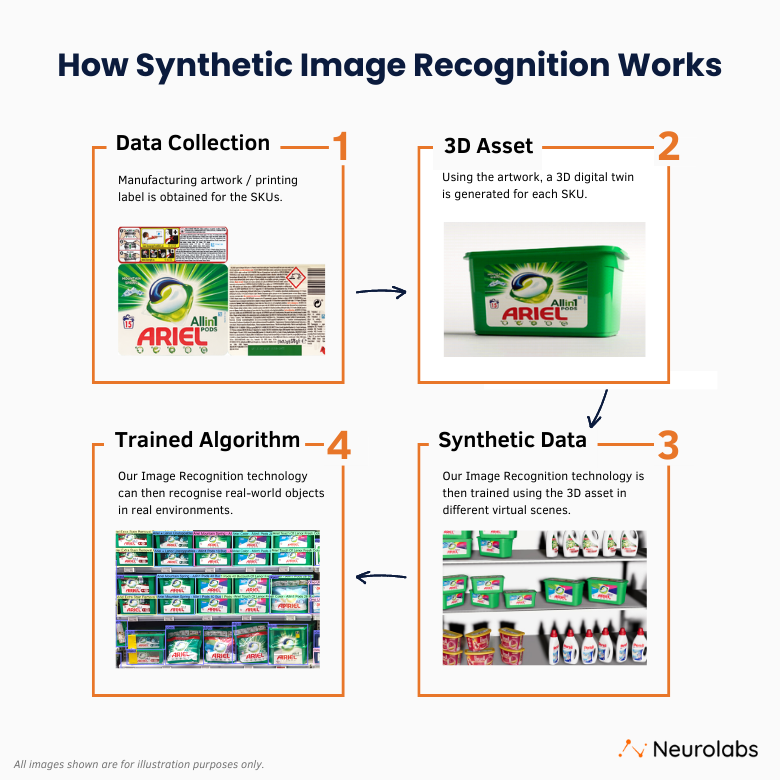
Using Synthetic Data in this way, to train Computer Vision models, is democratising access to Computer Vision technology. It is enabling the widespread adoption and scale of CV technology for automation in ways that traditional CV with real data never could.
Synthetic Data not only benefits the initial stages of a CV workflow, it streamlines the entire CV process.
Using Synthetic Data in this way allows you to build an SCV solution that excels where conventional solutions are limited in many ways:
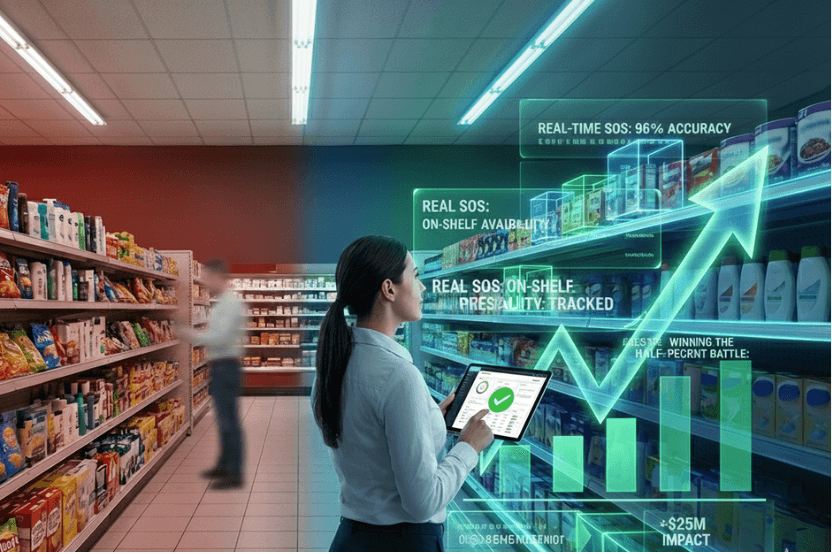
For Consumer Packaged Goods (CPG) brands, Synthetic Data enables the automation of visual-based processes such as Shelf Monitoring or Shelf Auditing in real-world retail environments.
The most innovative retail solution providers are already experiencing the benefits of using Synthetic Data by deploying Synthetic Computer Vision technology like ZIA by Neurolabs to automate supermarket operations.

At Neurolabs, we are revolutionising in-store retail performance with our advanced image recognition technology, ZIA. Our cutting-edge technology enables retailers, field marketing agencies and CPG brands to optimise store execution, enhance the customer experience, and boost revenue as we build the most comprehensive 3D asset library for product recognition in the CPG industry.

© 2026 Neurolabs. All rights reserved




%20(1).png)