
May 9, 2026
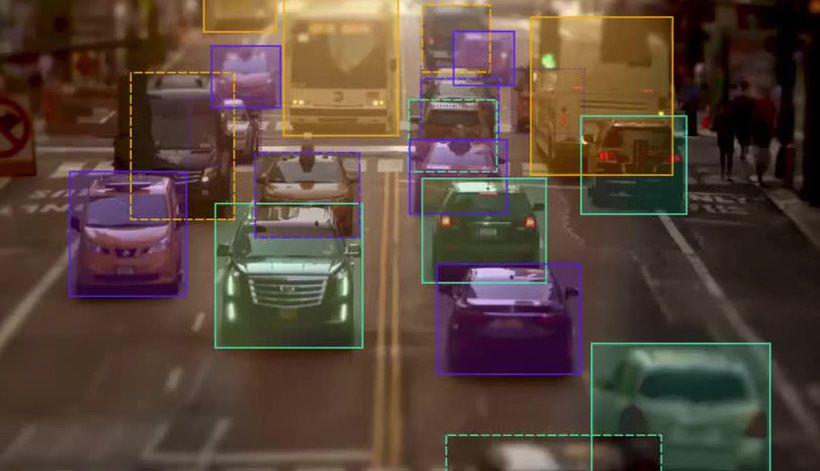
Computer Vision (CV) has come along way in the past few decades. From self-driving cars to Optical Character Recognition (OCR), it continues to transform the world around us.
Deriving meaningful information from digital images unlocks limitless automation potential. Yet, for a field of study which has grasped the attention of AI researchers since the 1960s, mainstream breakthroughs in Computer Vision have not been as drastic as the lofty advances that were promised.
The true potential of Computer Vision, as it stands, is only accessible to a niche of image recognition experts and machine learning specialists worldwide.
While the Teslas and Googles of the world can spend eye-watering budgets on their AI endeavours to develop next-level consumer products, there exists a large majority of non-technical industries, ripe for automation with the technology, that are hindered by an unnecessary barrier to adoption, data.

Attempts to democratise Computer Vision for widespread commercial use have been throttled by failure time and time again to optimise its largest dependency, the sourcing and preparation of high-quality training data.
Most CV solutions on the market today rely on a process that requires massive amounts of costly and time-consuming, real data as input. This makes it impossible to adapt and scale to the demands of the masses, and unrealistic for most companies to consider its use for domain-specific applications.
Simply put, traditional Computer Vision and image recognition technology will remain out of reach for the majority of companies until the data problem is solved.
Currently, it is estimated that only 1% of AI research is focused on the sourcing and preparation of data for AI models. The other 99% is focused on AI model training and algorithm optimisation. This is in spite of the fact that the data preparation stage of traditional Computer Vision, which requires vasts amounts of real data, takes up largely 80% of a developer’s time while 20% of their time is spent on training the model itself.
This disconnect between where a developer spends their time versus where advances are being made presents a very big problem for the future of Computer Vision.
On the flip side, it presents a very big opportunity for those who are willing to innovate with a more sophisticated and capable approach.
Rather than approaching the problem with both hands tied behind your back i.e. having a human painstakingly collect and label copious amounts of real data to train a Computer Vision model, take a step into the virtual world to generate that training data synthetically and experience a CV process that is faster, more cost-effective, and truly scalable.

Synthetic Computer Vision is a groundbreaking approach to image recognition that is powered by Synthetic Data.Synthetic Data is a virtual recreation of real world data that is used to train Synthetic Computer Vision models to detect real world objects.
For real world object detection, Synthetic Data encompasses rendered images and videos of a 3D, digital twin of a real world object including virtual scenes that it is placed in. This data represents the attributes of the object as well as possible environments in which it may be found in real life. It is used to train Computer Vision models to detect that real world object.
Using Synthetic Data to train Computer Vision models is known as Synthetic Computer Vision (SCV). Its use is leading to the widespread adoption, accessibility, and scalability of CV technology in ways that traditional CV with real data never could.

SCV simplifies the input stage of image recognition. Instead of manually collecting and labelling thousands of individual data points for one object, you create a computer generated object and scenery that you can generate vast amounts of images with to train a CV model.
Synthetic Computer Vision provides multimodal metadata (2D/3D bounding boxes, depth data, masks, etc.) at virtually zero cost. With SCV, bounding boxes are created programmatically from the get-go vs the long learning curve associated with traditional Computer Vision.

SCV is extremely robust as it eliminates the human annotation errors that are typical with conventional CV methods.
It is also extremely flexible as it captures real data variation with an easy to manipulate digital, 3D object as the training data.
Synthetic Data not only benefits the initial stages of a CV workflow, it streamlines the entire CV process.

SCV always starts with high quality data. Step one is to create a digital twin of the real world object.
Take, for example, a supermarket product or Stock-Keeping Unit (SKU). In order to generate Synthetic Data for a product, we first create its virtual doppelgänger using its real world packaging in 3D modelling software.

Using Neurolabs, we can upload the digital twin of the product to the platform to be used along with thousands of other products to train a Computer Vision model for our chosen CV use case.

With a digital twin in hand, we can use it to create a Synthetic Dataset.
Using the same software that we used to create the virtual, 3D version of the product, we build virtual scenes or digital replicas of real world environments in which the object can be placed. This helps create environmental context for the training stage.Once we have our digital twin and virtual scenes, we can render as many images and videos, with infinite variations of the products and their environment, as we want. A collection of these rendered images and videos makes up the Synthetic Dataset which will be used to train the Computer Vision model.As we are working with Synthetic Data, we aren’t limited by the data collection constraints of reality. We can simulate any position or condition for the product using its digital twin. We can also simulate whatever background we want using variations of the virtual scenes. In essence, the form and quantity of data is limitless.There are three specialised techniques that the Neurolabs platform provides to generate Synthetic Datasets:
Machine Learning algorithms will create a diverse mix of data for the Synthetic Dataset automatically, cutting even more time from the process.

Armed with a Synthetic Dataset, you can now use it as the training data to train a Computer Vision model to detect real products in the real world.
For example, you could use a Synthetic Dataset containing digital versions of supermarket products to help train a CV model to carry out Shelf Monitoring or Shelf Auditing in very different, real-world retail environments.
Using Neurolabs product, the training process is automated and easy to test on platform.

Training a precise Computer Vision model is seamless with Synthetic Data.
The result is a fully trained Synthetic Computer Vision model that is as simple to deploy to a real world, production environment as making a call to an API endpoint.
Neurolabs makes the whole process simple by providing all of the data generation and SCV model training via our platform. The product then applies an iterative training process to improve the synthetic training data using the models themselves.
Using Synthetic Data in this way allows you to build an SCV solution that excels where conventional solutions are limited in many ways:

Using Synthetic Data, a Synthetic Computer Vision model can be deployed at speed to detect any real world object such as grocery store products.
Neurolabs has been deploying Synthetic Computer Vision models in the real world for two years now.
Our Machine Learning experts pitted a Computer Vision model trained using real data against one that was trained using Synthetic Data. Specifically the test focused on the task of object localisation.
For the real data, SKU110K, an open source dataset of mobile images from supermarkets, released in 2019 by Trax, was used. They benchmarked the performance of a pre-trained model on the SKU110K dataset. This real dataset contains more than 10,000 manually acquired images. The estimated cost of collating this real dataset is about $20,000. A mAP (Mean Average Precision) of 60% mAP was reached when tested on a new real dataset from a real world grocery store.

After generating 1,000 Synthetic images using Neurolabs’ Synthetic Data generator, the team observed a mAP of 65% as tested on the real data from the real world supermarket. The team randomised the lighting, camera locations and position of the objects. They used physical simulations to create more realistic structure when creating the datasets.
When compared with the real data results, they observed a 5% increase in mAP using Synthetic Data. This resulted in a 100x decrease in cost and time associated with the deployment, thus making the solution much more scalable.

Using Synthetic Data proved to be the superior option when deploying Computer Vision in a real world environment. Not only did the mAP improve but the cost and time involved in the project was radically reduced.
Furthermore, applying Neurolabs’ data mixing and domain adaptation techniques increases the model’s mAP performance to 80%. This was done using a mix of Synthetic and real data at a ratio of 100:1 i.e. using 1,000 synthetic images with 10 real annotated real images.

Commercial application of Computer Vision will continue to grow in the coming years. The smart use of the technology will become a necessity for any company that wishes to effectively automate visual-based tasks.
The most forward thinking companies understand the value of investing in the right image recognition tech stack. Innovating in this area will not only create organisational-wide process efficiencies but indeed create a competitive advantage for the organisations that deploy it.Synthetic Data is the future for a truly scalable and easily deployable Computer Vision solution.
Synthetic Computer Vision democratises automation potential that should not be reserved for an elite technical few but instead should be readily available to the masses to positively impact the world.
Retailers worldwide lose a mind-blowing $634 Billion annually due to the cost of poor inventory management with 5% of all sales lost due to Out-Of-Stocks alone.
Neurolabs helps optimise in-store retail execution for supermarkets and CPG brands using a powerful combination of Computer Vision and Synthetic Data, called Synthetic Computer Vision, improving customer experience and increasing revenue.

.svg)
.svg)